
Tips for moving data-driven projects from local to production
Antonio Fernández
Most data scientists’ routines consist of opening a notebook, loading some data from local or pointing to a company data lake, encapsulating this data within a data frame and running transformations and aggregations until obtaining the expected analysis result. This methodology is fast and efficient, and suits almost any data-driven case study where your main goal is to perform an exploratory analysis to gain insights about data, assess your feature importance or benchmark different machine learning models. However, code developed in notebooks normally tends to chaos and low reproducibility, leading to some bad practices or assumptions that are not realistic if code was developed by a team and deployed in a production environment to be consumed by clients.
Over the years, I have experienced this process for myself. From developing inside Jupyter notebooks, coding long cells and saving configurations as variables, I progressively gained a more software development oriented vision, and transitioned to more modularised, tested and reproducible software, where notebooks have been exiled, using them only to plot visualisations and debug specific code. From a data point of view, real time processing introduces some concepts not present in historical data processing, which opens a new world of challenges: computation, delays or interoperability between many micro-services. Along this journey, I have explored many different technologies and internalised some best practices. The following tips might be useful for you in case you are shifting from research and experimentation to software product development, or simply moving from batch processing to real time. As a reminder, all the tips and recommendations discussed in this posts are entirely based off my own experience productising data driven applications in aviation, and in most of the cases these tips depend on the context of the project and/or problem to solve.
Upgrade your technology stack
A wide variety of technologies exist to analyse historical data and almost all of them are perfectly valid to gather insights from your data or to train a predictive model. The technology trends point to Python as the predominant technology for data science over other frameworks like R, Java, Matlab and Scala. However this flexibility to “develop anything using any language” doesn’t fit very well in reality, particularly in the streaming world. When processing streams, you have two suitable strategies: process data in very small batches (a.k.a micro-batches) and perform processing iterations sequentially; or natively, which consists of listening for upcoming events continuously. The predominant frameworks that enable streaming processing are Apache Flink, Apache Storm, Spark Streaming and Kafka Streams. Most of these frameworks support Java, Scala and Python, with Python being a bit behind in terms of features and performance for Spark Streaming and Flink (mainly doing stateful operations), and Java being the only language supported by Kafka Streams, with a port to Scala.
Either due to the desired analysis itself, or because of the high data volume to process, most use cases demand a lot of computational power and parallelisation, so in my humble opinion, Spark is usually the best choice. Around research and experimentation environments, the most popular stack is probably the Python state-of-the-art data science toolkit based on pandas, numpy, scikit and matplotlib. When moving an experiment to a product, although these libraries support the integration of technologies like Kafka or sockets, its performance can be affected by how your problem scales, and you should consider other technologies that focus more on covering the streaming part in a efficient and fault-tolerant way. There are a lot of technologies that can fit your particular solution. For instance, if your use case is very tied to Kafka, you should try Kafka Streams; or if the problem you aim to solve is quite simple, maybe Apache Storm is the best choice. The available documentation is also an important aspect to consider when choosing your streaming technology stack, and the lack of it is probably shared by all streaming processing frameworks mentioned above.
My humble recommendation for a data science team that is used to working with Python and notebooks would be to transition slowly from pandas to the Spark API at early stages of productisation. You can directly learn PySpark from scratch (it is very similar to pandas), or try an interoperability library to simplify the migration between both APIs, such as Koalas. If at any point of your roadmap you plan to iteratively increase your training sets, engineer new features, retrain your models and deploy them as a service into production, you would need robust ETL pipelines design that fits not only for processing historical data, but also for streaming (in line with the Lambda architecture design pattern). You can keep your experimentation and model tuning using pandas and notebooks, but it’s important to start thinking about the ETLs design, how features are going to be calculated to consume the models? Is it worth it to compute certain features in real-time when its impact on prediction accuracy isn’t very high? How ready is your data processing code (ETL) to process years of data, but at the same time receive new data in real-time, compute the features and consume the model? At intermediate stages of productization, where ELTs imply many data wrangling steps composed by complex aggregations and stateful operations, you probably should think about migrating to Scala. Apart from the huge performance boost it offers, Scala is considerably more advanced than PySpark’s library development, especially for the streaming part, and may help you avoid some limitations that might affect your real-time implementation in the long term.
Deployment environments, configuration and releases
When working on research, where experimentation is completely open and there is low risk of messing up code and crashing the whole application, everything is permitted as long as code works. On the other hand, while developing a product, it’s mandatory to have isolated environments at least for development and production, guaranteeing a strict quality of service while implementing and testing new product features. Usually experimentation is done locally, where nobody is consuming your services and there is no risk. Normally most systems are managed through at least three environments: development, staging (or pre-production) and production:
- Development: Here is where new code pull requests are implemented, usually local to your computer. Regarding data access, it should read/write from local services or remote databases where information is isolated from the rest of the environments (use data version control – DVC). Many members from your team will be working on separated branches, and nothing will affect other environments. The main requirement to satisfy before closing a development branch into main would be to ensure that it compiles and works as expected locally.
- Staging: This should be similar to production in terms of performance and deployment. Here the different branches that were closed into main will be deployed, being able to break other services that interact with your deployment, though these errors must never be perceived in the production environment. The main goal of this environment is to test not only the newer implementations of a component but also to integrate them with other micro-services that might be reading or writing related data.
- Production: This environment represents the live status of your project. After successfully passing tests and validations in staging, code can be moved into production. Normally you should schedule releases to move changes from staging to production iteratively in order to minimise unexpected crashes and debugging. You can also create a separated QA environment to ensure quality of service.
Each of these environments would require a particular configuration, such as credentials to read data from data lake, endpoint paths to store information or constants to define a particular business concept to label in data. Following the twelve factor rules, everything that is likely to vary between deployment environments should be stored as environment variables. Furthermore, constant values that belong to the application configuration but often remain the same among environments must be always stored as config files avoiding to store them directly in the code. Another important fact to consider when building a multi-environment application is the orchestration to the different micro-services deployment. Tools like Apache Airflow support this step when you have a lot of services to deploy, each of them with particular configurations.
At early stages of productisation, I recommend considering local as the development environment and educating your development team to follow up a PR review methodology. This will force developers to review code from others, so the majority of the team can agree with proposed changes. In parallel, you can start setting up some automations (e.g. DevOps) to your code repositories that periodically compile your code repository, pass some tests and deploy it into a server (staging). Even if your code is just a “hello-world” example, things are much easier if you first configure and automate the deployment, and afterwards focus on increasing product functionalities. In an intermediate stage of productisation, you should move your prototype from staging to a more consolidated production environment, and give access to some potential users or stakeholders.
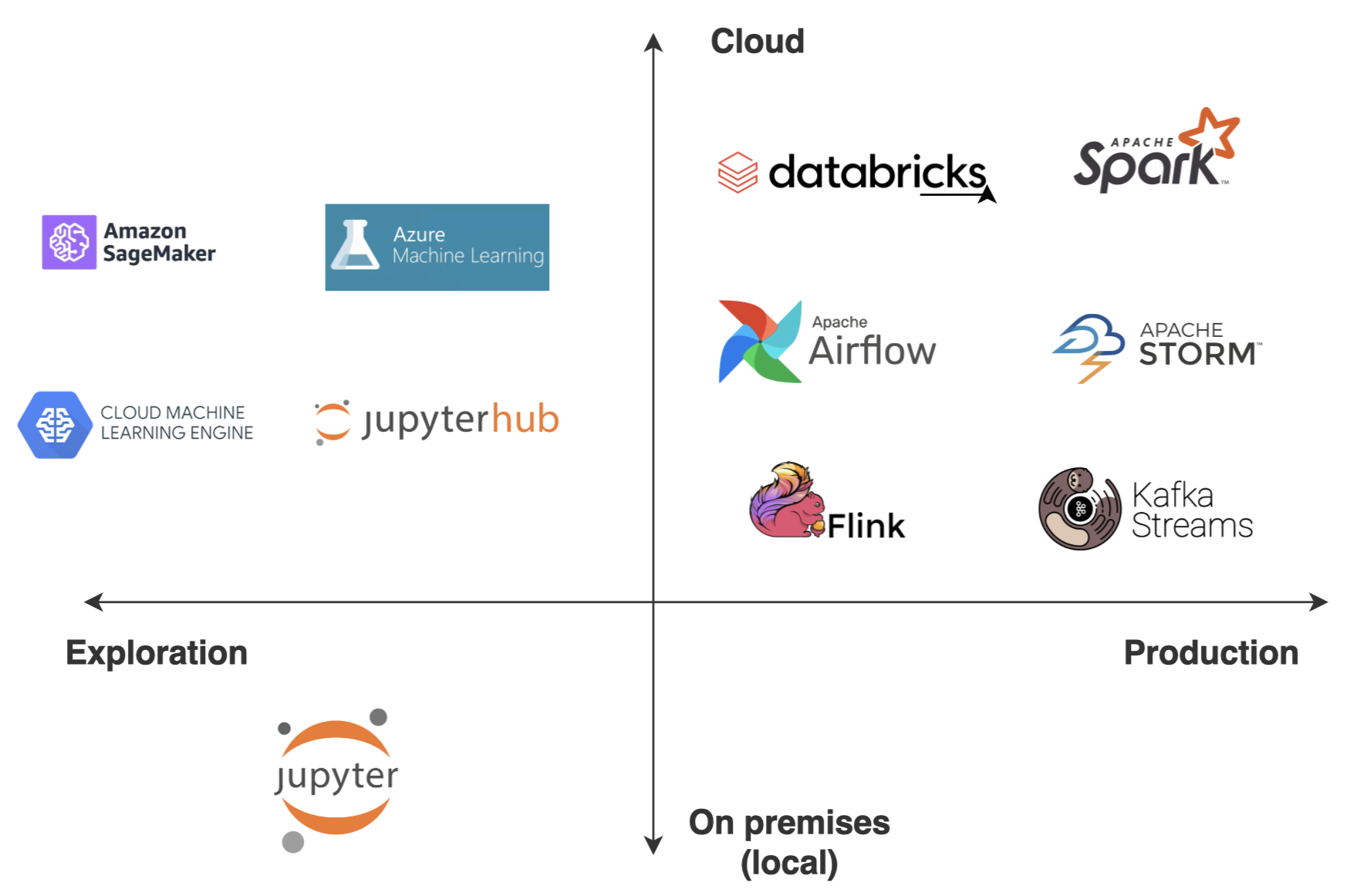
From notebooks to IDEs
Notebooks are great when you are developing locally and if you are the only person coding. Moreover, since notebooks are kind of embed HTML websites, sometimes its versioning can be tricky using Git. When you start working as a team, it’s crucial for any member to contribute to the code, and merging conflicts might arise if code is embedded in long cells or files that everyone needs to touch. That’s why notebooks are incredible for experimentation and probably the best way to extract insights from data using plots, though they complicate software development and team collaboration. There are plenty of IDEs available, so you can choose the one that best adapts to you. I personally use Visual Studio Code by default, and particularly IntelliJ for coding in Scala.
At early stages of productisation, I recommend first trying to remove all your functions from cells and packaging them as modules (in the case of Python), and afterwards importing these functions from notebooks. This way, the versioning of your submodules and functions can be tracked through files using Git. Moreover, you should start looking at software development design patterns in order to create robust classes that enable to modularise your ETLs, composing connectors to extract and load information from the data lake, and that enable you to implement agnostic transformations so functionality can be applied to data frames regardless of the business logic.
Observability to build fault-tolerant applications
Last but not least, observability is one of the main issues to worry about when building ready-to-production software. We understand by observability the ability to measure a system’s current state based on the data it generates, such as logs, metrics and traces. The observability relies on exploiting the records generated by all the activities deployed in every micro-service to understand what’s happening across all the environments and among the different technologies used. This in turn helps detect and resolve issues that can keep systems efficient and reliable while ensuring minimum quality of service to your users. Sometimes observability is simply called monitoring; however, they are different concepts. In a monitoring scenario, normally you configure dashboards to alert you if the thing goes wrong before they occur. In an observability scenario you can explore what’s going on and quickly figure out what’s causing instability, without necessarily anticipating the issue beforehand.
My humble recommendation would be to centralise your micro-services logs and metrics in order to track the status of every micro-service deployed on each environment. This will allow you to indirectly anticipate crashes, and monitor delay, performance and failures, observing your application as a whole, even if it’s composed by other small pieces of code, using different technologies. Try to automate alarms based on common metrics such as resources consumption, delay perceived in messages or processing times degradation. Dashboards can also be very useful tool to track the evolution of metrics, especially for when performance worsens over time
Conclusion
In this post, we reviewed some tips when moving from local development, analyzing historical data using notebooks, to real-time deployment building, ready-for-production data driven applications. As I mentioned before, these tips are based on my own humble experience, and can’t be taken as the ground truth for all projects; however, they might be very aligned to those applications or lines of research for which the technology readiness level (TRL) is currently between 4-6 and moving forward to TRL 9. Hope you find these useful and stay tuned for most posts!
References
https://dev.to/flippedcoding/difference-between-development-stage-and-production-d0p
Author: Antonio Fernández


